AI牛马这么快就学会了“摸鱼”,真牛马泪崩

大伙儿发现没,现在的 AI “摸鱼” 的现象日益频出,前阵子有人花大价钱给 OpenAI 充了 200 刀的会员,就想瞧瞧 GPT-5 到底多厉害。结果扔过去一道算术题,它直接算崩了。你说气人不气人,这 200 刀的 AI,居然还没那人 20 块的计算器靠谱。
但那人记得 GPT-4 刚出来的时候,还让它算过高数呢,难道升级把智商给升没了?于是那人又丢了道微积分过去,嘿,人家换元法用得那叫一个溜,看起来还真没毛病,评论区的大学生们可以来验验真假。
所以啊,两次算术用的都是 GPT-5,怎么还对那人 “见人下菜碟” 呢?那人本来以为是 OpenAI 飘了,结果上网一查,发现这事儿还真不是 GPT 一家这样,甚至有点行业趋势的意思。
前几天美团发布的开源模型 LongCat,就说自己用了个 “路由器” 来提高效率;DeepSeek 3.1 发布的时候也说了,自己一个模型能有两种思考模式;同样是 AI 巨头的 Jimina,在 Jimina 2.5 Flash 发布时也引入了相似模式,让模型自己决定怎么 “用脑”。总的来说,大家都在让自己的模型该思考时再思考,该偷懒时就偷懒。
这么做的原因也很好理解,就是为了省钱。从 OpenAI 发的资料来看,通过这种让模型自己决定要不要思考的方式,省下来的 “坑” 还真不少,GPT-5 输出的 “坑” 数就少了 50% 到 80%。BBC 官方发的图表里也显示,新模型的 TOX 消耗下降了大概 20% 到 50%,这可是省了一半呢。
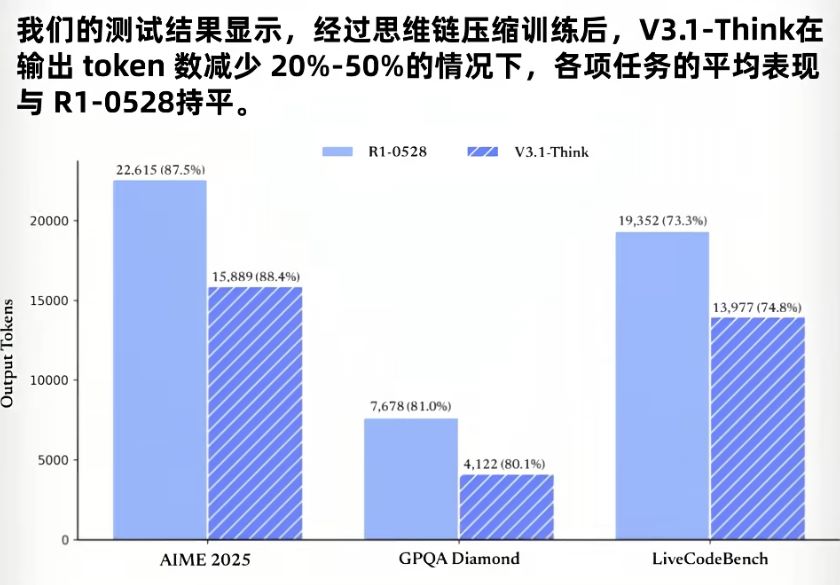
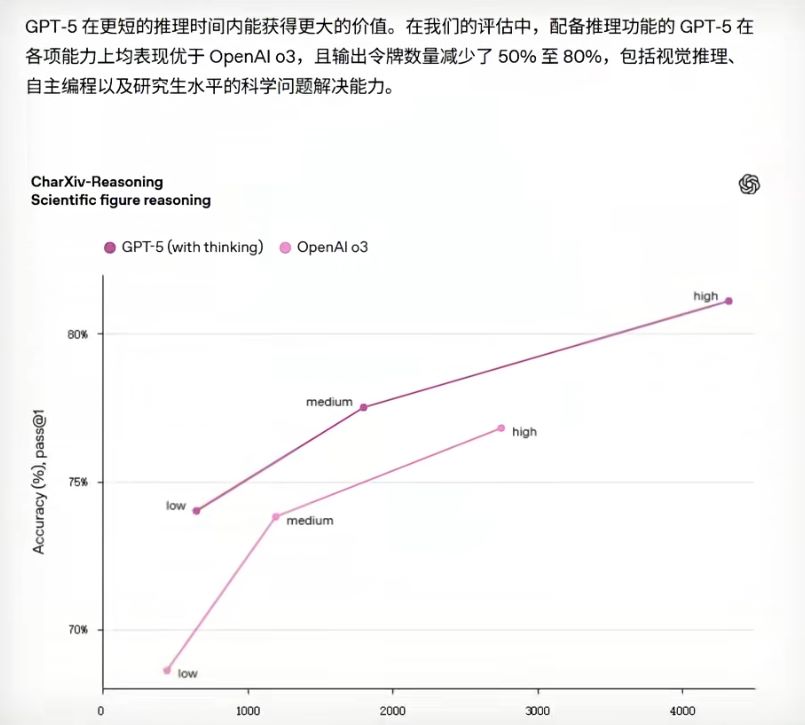
这概念普通人可能没什么感觉,但对 OPPO 这样的大公司来说,可能就是一大笔开销。早年央视就报道过,GPT 每天耗电超过 50 万度,在这么庞大的基础下,省出来的部分够一个上万户家庭的小镇用一天了。难怪奥特曼在网上跟网友说,网友们跟 GPT 说声谢谢都要花他上千万美元。
之前的高级模型,一句 “谢谢” 都能让它思考几分钟,确实有点浪费。那 AI 这 “看题下菜” 的能力到底是咋来的呢?OpenAI 没公布具体原理,但 2023 年有篇论文专门分析了这个问题。在 GPT-3.5 出来那阵,大模型还不会自己调节思考能力,每个问题都能让 AI 一个劲儿地烧脑。为了提高效率,研究者想出了个叫 “感知路由器” 的模块,它本质上就是在混合模型里塞了一个小巧的语言模型。
在前期训练时,“路由器” 就跟刷题似的,对使用哪个模型最佳做出自己的预测 —— 哪个模型适合深度研究,哪个模型适合快速思考。当然有标准答案,模型会把这个预测分和标准答案对比,计算出两者间的误差,接着通过微调 “路由器” 内部的参数来减小误差。等它刷了数百万道题之后,就逐渐学会怎么给提示词分配合适的模型了。当一个新提示词进来,AI 内部的路由小模型就会先扫一眼,评估一下这个问题配不配让它动脑。因为 “路由器” 比较轻量级,所以这个评估过程几乎是一瞬间的事。
除了这种思路,AI 还有一种偷懒办法,就是把不同的 token 导向不同的神经网络。像美团 LongCat 就采用了这种方法,从报告来看,他们用了一种叫 “零计算专家” 的机制。
通常来说,当有人输入提示词之后,提示词会拆分成一个又一个的 tokens,交给模型内部的神经网络去处理。而 LongCat 在处理之前,会先把它交给一个小 “路由器”,这小 “路由器” 就像流水线上的调度员,收到 token 后会判断这 token 处理起来是复杂还是简单。
同时,它内部有许多不同分工的神经网络,我们叫它们 “专家”。这些 “专家” 有的喜欢做难题,有的喜欢做简单题,当然也有 “摸鱼界专家”。像那些没什么用的 token,就可以丢给那些 “摸鱼大王”,因为它们根本不需要怎么处理。这下你就知道 “零计算专家” 这名字是咋来的了,也能解释为啥大家都在说模型变快了。
总的来说,这种设计对模型厂商来说算是好事,不仅省钱还能提升训练效率。从用户角度来讲,模型更快了,价格也更便宜了。但有人觉得这玩意儿是把双刃剑,用不好还真会实实在在影响用户体验。

比如 GPT-5 刚上线时,这 “路由器” 就出问题了,用户发现自己怎么也调不出它的思考模式,问啥都懒得思考,摆烂似的只会 “对对对”,连蓝莓里有几个籽都数不明白。而且用户也有自己的喜好,很多人就是喜欢 GPT-4 那种啥都认真回应的劲儿,结果被一刀切了,搞得很多网友在网上哭诉自己失去了一位 “朋友”。
这不就变相说明,发布的时候 “路由模型” 就没调好吗?再说 LongCat 确实很快,但在思维深度上还是比不过其他大模型。像有人同时给 LongCat 和 DeepSeek 丢了同一个问题,LongCat 刚开始唰唰出答案,却没解读出这句话的幽默感;而 DeepSeek 虽然慢了点,笑点解析得却很清楚。就像有人说口算很快,问那人 “114 乘 5 加 14 等于多少”,那人说 “1919810”,就问你快不快吧?
当然,对于 “路由器罢工” 也有些解决办法,就是在提示词里加入 “深度思考”“auto sync” 这些字眼,“路由器” 收到后会尽量调用更强大的模型。不过这也只能说是治标不治本,多用几次可能就 “拼尽全力”,实在没办法叫醒了。这时候就说明它确实罢工了,只能再等几个小时再来试试。
所以说到底,方向是好的,技术是新的,但现阶段的体验也确实只能算 “还行”。当然啦,大模型的成长速度比人们想的更快,更好、更快的模型说不定已经在路上了呢。