一个 “线性硬刚”?一个 “立体开挂”?自回归模型和扩散模型之争究竟谁更胜一筹?

你知道吗?比现有大模型快 10 倍的扩散语言模型,是今年上半年的热门研究方向。人类表达时,往往先有核心意思和关键词,再串联成句,并非逐字想好。可现在的大模型为何要逐字输出,不能先定整体再优化细节呢?
扩散语言模型(diffusion language)给出了答案。它融合了图像扩散模型与大语言模型的优势。图像扩散模型生成时,是从纯噪音图像逐步去噪得到成品,类似木头雕刻先构整体再修细节,扩散语言模型也如此:先生成整体框架,再不断去噪优化,而非传统模型那样从左到右逐字蹦。
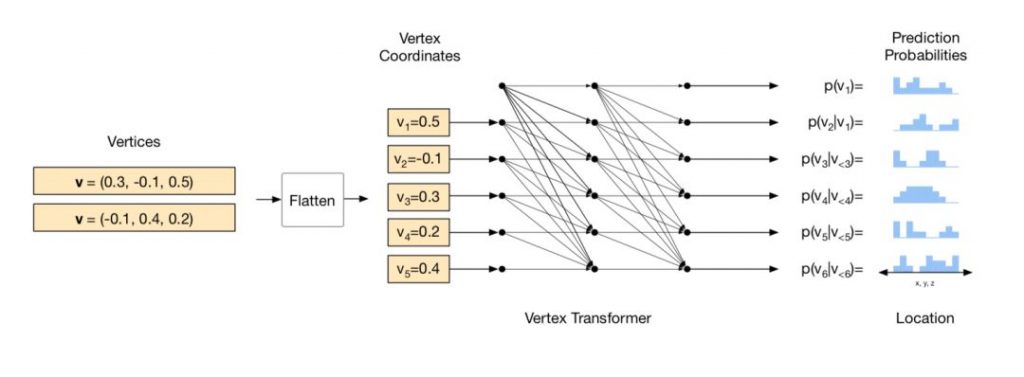
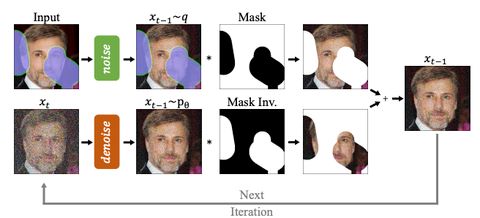
自回归模型 vs 扩散模型:犀利对比
- 自回归模型:主打 “挤牙膏式输出”,从左到右一个字一个字蹦,像写书法只能顺笔画,错了没法改,堪称 “一步错步步坑” 的倔强选手。
- 扩散模型:玩的是 “先搭骨架再填肉”,先搞出整体框架再精修,错了能回炉重造,像雕刻师边雕边改细节,效率拉满还带 “后悔药”。
简单说,一个是 “线性硬刚”,一个是 “立体开挂”。


它速度极快,14 步就能完成自回归模型 75 步的写代码任务。且容错性强,生成的词有误可弥补,不像传统模型一旦生成就无法更改。实验显示,相同数据和参数量下,扩散语言模型知识学习更深,部分指标优于传统自回归大模型。更惊人的是,即便训练数据重复 480 遍,它的表现仍能提升,对数据挖掘更深入。
传统模型因逐字生成,注意力矩阵是三角形,无法关联未生成词汇;扩散模型并行生成,注意力矩阵是满的,参数量更紧凑,能用更小参量捕捉更多信息。
不过,它尚未替代自回归大模型,除了技术新、架构和数据未适配,还因并行生成对算力要求更高。
目前已有技术结合两者优势:句子间自回归生成,句子内用 block diffusion 快速填充,更贴近人脑思维。
这个技术会是 AI 行业的下一个突破点吗?让我们拭目以待。

总结一下就是:
“扩散语言模型(diffusion language model)”,它融合了图像扩散模型与大语言模型的优势,生成速度比传统大模型快 10 倍(14 步完成自回归模型 75 步的写代码任务)。其原理类似 “木头雕刻”:先构整体框架,再逐步 “去噪” 优化细节。相比传统模型,它能纠错、知识学习更深、数据挖掘更透(数据重复 480 遍仍能提升表现),但对算力要求更高。目前已有技术结合两者优势(句子间自回归、句子内块扩散),更贴近人脑思维。