盘点国内6大“让照片开口说话”AI项目,北大开源新项目,数字赛道再添 “猛将”InstructAvatar

在竞争激烈的数字赛道上,又一位 “重量级选手” 强势入局!这次的主角,是北京大学刚刚开源的一个项目。此项目一登场,便以独特的技术亮点吸引了众人目光,尤其是其在面部模拟方面的创新,令人眼前一亮。
传统的唇形同步技术已不新鲜,但北大这个项目做到了 “高仿真”,不仅嘴型与声音高度匹配,而且极为自然,仿佛屏幕里的人物就在真实说话。这还不够,该项目的厉害之处在于,它赋予用户通过提示词来控制人物表情和头部运动的能力。只需简单输入几个关键词,就能让虚拟角色展现出喜怒哀乐,或是点头、摇头等各种头部动作,极大地拓展了虚拟角色的表现力。如果真能按照展示的效果完全开源,无疑将为相关领域带来新的活力,十分值得期待。
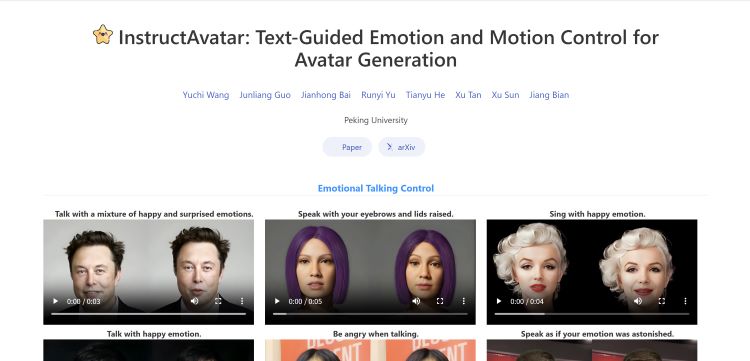
【一】InstructAvatar 是北京大学团队推出的创新头像生成模型,通过自然语言引导,能对 2D 头像的情感和面部动作进行精细控制。
InstructAvatar 官网:https://wangyuchi369.github.io/InstructAvatar/
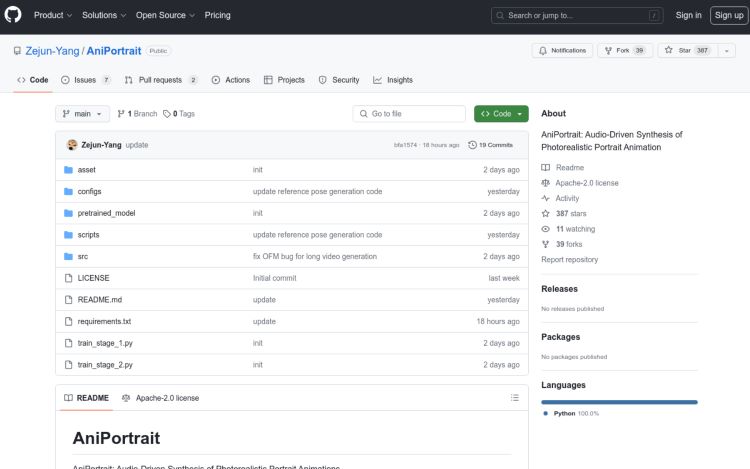
【二】AniPortrait 是腾讯推出的一个音频驱动的真实肖像动画合成框架。
ANIPORTRAIT官网:https://github.com/Zejun-Yang/AniPortrait

【三】MuseTalk 是腾讯音乐天琴实验室开发的一款实时高质量音频驱动的口型同步模型,主要用于虚拟人口型生成。
MuseTalk 的 GitHub 网址:https://github.com/TMElyralab/MuseTalk

【四】SadTalker AI 是一款由西安交通大学开源的人工智能模型,主要用于将静态图像转换成动态视频,使图像中的人物能够根据音频内容进行讲话。
SadTalker 的官网:https://sadtalker.github.io/
【五】EMO 是一个由阿里巴巴集团智能计算研究院开发的AI图生视频模型。
它被称为”EMOTEPORTRAIT ALIVE”,能够通过一张照片和一段音频,或者视频,生成人物说任何话或唱任何歌曲的动态视频。
阿里巴巴 EMO GitHub 地址:https://github.com/HumanAIGC/EMO

【六】VividTalk 是由南京大学、阿里巴巴、字节跳动和南开大学联合开发的一个人工智能项目,旨在实现基于单张照片和音频的说话头像视频生成。
VividTalk项目主页:https://humanaigc.github.io/vivid